How JavaScript-based pagination can harm your SEO
JavaScript-based pagination may look slick, but it can quietly break your SEO. If Google can’t crawl or index paginated content properly, users (and rankings) suffer. This article explains why JS pagination causes issues, how search engines handle it, and what you can do to make your content discoverable and indexable again.
(and how to fix it)
TL;DR
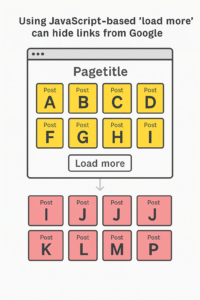
If your blog or product category pages use a “Load More” button or infinite scroll powered by JavaScript, and the additional content is not discoverable through <a href=""> links or separate URLs, there’s a high chance search engines can’t access or index this content. This leads to lower visibility in search results. Make sure to expose all content through crawlable links or supplement with proper internal linking.
Why this matters
In the pursuit of sleek UX, many websites—especially blogs and ecommerce platforms—implement JavaScript-based pagination or infinite scrolling on category pages. Examples include:
- Blog category pages showing 8 posts with a “Load More” button
- Product listing pages (PLPs) in ecommerce with endless scrolling
- Case study pages that reveal more entries only after interaction
If these interactions load content via JavaScript (e.g., with a button element), and do not update the URL or expose crawlable <a> links, Google and other search engines may never discover that content.
Key takeaways
- JavaScript actions don’t create crawlable links
A button like<button onclick="loadMore()">does not create a crawlable path for Googlebot unless paired with link discovery or rendering fallback mechanisms. - Crawlers may miss dynamically loaded content
Unless you use proper server-side rendering or pre-rendering, bots won’t see the extra content added via JavaScript. - URL fragmentation and discoverability
Without separate paginated URLs (/category?page=2), there’s no direct path for bots to follow or for users to share/bookmark. - The SEO cost of hidden content
Any content not exposed to search engines is content that won’t contribute to rankings or traffic, no matter how valuable it is.
How to test if this affects your site
- Disable JavaScript in your browser
Visit your category or PLP pages with JavaScript disabled. Can you still navigate to all content? If not, you have an SEO problem. - Use Screaming Frog SEO Spider
Run a crawl in non-JavaScript mode. If only a fraction of your blog posts or products are discovered, the rest are hidden. - Check Google Search Console → Coverage Report
Look for “Discovered – currently not indexed” or low indexation on blog/product pages. - Use “site:” operator in Google
Searchsite:example.com/blogand compare the number of results with the actual number of posts. A major mismatch can be a red flag.
Best practices and recommendations
✅ Use crawlable <a href=""> links
Pagination should use standard anchor tags linking to pages like /blog/page-2, not JS buttons.
✅ Implement rel=”next” and rel=”prev” (if applicable)
While no longer a directive, it still helps indicate logical structure to crawlers.
✅ Provide static navigation fallbacks
Ensure a basic paginated structure exists that bots can crawl even if JS fails.
✅ Use pre-rendering or server-side rendering (SSR)
If you must use JavaScript, use SSR frameworks or services (e.g., Next.js, Nuxt, Prerender.io) to expose the content to bots.
✅ Crosslink to deep content
Internally link to deeper blog posts or product pages from high-authority sections (e.g., homepage, pillar pages).
✅ Consider an HTML sitemap
List all blog posts or products in an HTML sitemap that’s accessible and regularly updated.
When this problem typically arises
This issue is most common on:
- Blog category pages
- Ecommerce product category pages
- Portfolio and testimonial grids
- Case study listings
- Events or news archives
Basically, any content hub that uses a grid-based interface with more data than initially shown is at risk—especially when “Load More” functionality is implemented via JavaScript-only interactions.
Final thoughts
Modern web UX shouldn’t come at the cost of discoverability. Hidden content is wasted content. Always test your pagination structure from the perspective of a search engine crawler. If your most valuable articles or products live beyond a JS-only button, it’s time to reconsider your setup.